Introduction:
This post is part 1 of a 3 part series. I’m going to walk through setting up a Flask API project, adding a React frontend to the project and then adding some data visualization to the React frontend.
If you’ve seen any of my previous blog posts, I’ve discussed setting up SQL databases, using Redis databases, setting up dashboard applications – so the next natural step would be to discuss displaying some of this data I’ve ben hoarding.
Here are the other chapters:
- Adding an API to your Flask project.
- Adding a React frontend to your Flask project (this section).
- Adding data visualization to your Flask app with React Victory charts.
Flask is great for creating server side applications and API projects.
In this blog post, I’m going to discuss some of the basic principals of adding an API to an existing Flask project. As most people who are familiar with Flask, are already familiar with Miguel Grinbergs microblog application, I’ve cloned his project repository we will add an API endpoint to it.
Flask large application structure:
Here’s the project structure for a large Flask application (this is Miguels’ microblog application).
For this project – we will be adding in the app/api_1_0 folder and associated code. We’ll also update the config.py to attach the API routes to our app.
| config.py
| microblog.py
|
+---app
| cli.py
| models.py
| __init__.py
|
+---api_1_0
| routes.py
| __init__.py
| load_junk_data.py
|
+---main
| forms.py
| routes.py
| __init__.py
|
+---static
| loading.gif
|
+---templates
| base.html
| index.html
| user.html
|
\---errors
404.html
500.html
Python data structures:
Let’s look at some Python dictionary data structures and I’ll show how I would add these to an SQL database. We’ll start off with a generic data structure.
Here we have a data structure (a Python dictionary), detailing information of some type of company. The Company dictionary contains a key “FINANCE”, which contains a list of Finance dictionaries.
{
"BUSINESS_TYPE": "Manufacturing",
"COMPANY": "Stark Industries",
"COMPANY_CEO": "Pepper Potts",
"FINANCE": [
{
"Q1_EARNINGS": 7825000000.0,
"Q2_EARNINGS": 7825000000.0,
"Q3_EARNINGS": 7825000000.0,
"Q4_EARNINGS": 7825000000.0,
"YEAR": 2018
},
{
"Q1_EARNINGS": 7825000000.0,
"Q2_EARNINGS": 7825000000.0,
"Q3_EARNINGS": 7825000000.0,
"Q4_EARNINGS": 7825000000.0,
"YEAR": 2017
},
{
"Q1_EARNINGS": 7825000000.0,
"Q2_EARNINGS": 7825000000.0,
"Q3_EARNINGS": 7825000000.0,
"Q4_EARNINGS": 7825000000.0,
"YEAR": 2016
},
{
"Q1_EARNINGS": 7825000000.0,
"Q2_EARNINGS": 7825000000.0,
"Q3_EARNINGS": 7825000000.0,
"Q4_EARNINGS": 7825000000.0,
"YEAR": 2015
}
]
}
Once we define the data structure, the next step for a Python developer would be looking at how to nest several Company dictionaries, inside another wrapper dictionary.
What use would our database be if we can only store 1 company – we want to be able to store data for a huge amount of companies – the more the better 🙂
{
"DATA": [
{
"BUSINESS_TYPE": "Manufacturing",
"COMPANY": "Stark Industries",
"COMPANY_CEO": "Pepper Potts",
"FINANCE": […
]
},
{
"BUSINESS_TYPE": "Multinational Conglomerate",
"COMPANY": "WayneCorp",
"COMPANY_CEO": "Bruce Wayne",
"FINANCE": [ …
]
}
]
}
SQL Alchemy:
In SQL terms our Company dictionary is an example of a one-to-many relationship. 1 Company contains many Finance dictionaries.
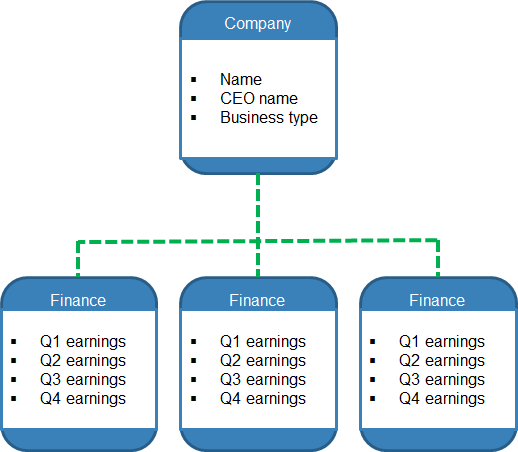
Let’s look at how we would create this data structure with SQL Alchemy.
Creating the Company table:
The actual database connections are made in the config.py file – I’ve discussed this here before.
To add a database table, we create a class in the app/models.py file – we can then create instances of that class in our code.
I am loading the Python dictionaries via a function called load_junk_data – I wish I’d thought of a more professional name for this file but here we go:
app/models.py
class Company(db.Model):
__tablename__ = 'company'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(140))
company_ceo = db.Column(db.String(140))
business_type = db.Column(db.String(140))
finances = db.relationship('Finance', backref='finance', lazy='dynamic')
def __repr__(self):
return '<Company {}>'.format(self.name)
What is this code doing?:
- We are creating a class object named “Company”:
- The Company class inherits the properties of the db.Model parent class.
- We are giving the class a table name of “company”.
- The SQL table “company” will be created when db.create_all() is called in config.py
- The “id” column will be the primary key.
- We are defining a “finances” column, which is a database relationship type:
- It has a back reference to the “finance” table (we will make this next).
- Setting the parameter lazy=dynamic is a dynamic loader, this will return a Query object when we call the filter() function.
Adding the Company object:
Now that we have created the table – how do we populate the data? Let’s create an instance of the Company object and store it in our SQL database.
Creating an instance of the Company object:
app\api_1_0\load_junk_data.py
my_wayne_company = Company( name = company_waynecorp["COMPANY"], company_ceo = company_waynecorp["COMPANY_CEO"], business_type = company_waynecorp["BUSINESS_TYPE"] )
First we populate the “my_wayne_company” object from our Company dict.
Adding a Company item to the database:
Now we can add the object into the database.
db.session.add(my_wayne_company) db.session.commit()
Adding the Finance object:
Now that we have saved a Company object – we need to create some Finance objects and attach the finance data to their respective companies. The Finance table will represent the “many” part of our one-to-many relationships.
Creating an instance of the Finance object:
app/models.py
class Finance(db.Model):
__tablename__ = 'finance'
id = db.Column(db.Integer, primary_key=True)
year = db.Column(db.Integer, default=1999)
q1_earnings = db.Column(db.Float)
q2_earnings = db.Column(db.Float)
q3_earnings = db.Column(db.Float)
q4_earnings = db.Column(db.Float)
company_id = db.Column(db.Integer, db.ForeignKey('company.id'))
def __repr__(self):
return '<Finance {}>'.format(self.id)
What is this code doing?:
- We are creating a Finance class object:
- The Finance class inherits the properties of the db.Model parent class.
- We are giving the class a table name of “finance”.
- We have previously defined this reference in the Company tables’ “finances” column.
- We are defining a “company_id” column, which is an integer type:
- “company_id” is a also a foreign key referencing the “id” column of the “company” table.
Adding a list of Finance items to the database:
Each Company object will have many Finance objects attached to it.
We can can create 2 instances of the Finance object, in a similar way to how we created an instance of the Company objects.
app\api_1_0\load_junk_data.py
wayne_finance_y1 = Finance( year = wayne_finance_y1["YEAR"], q1_earnings = wayne_finance_y1["Q1_EARNINGS"], q2_earnings = wayne_finance_y1["Q2_EARNINGS"], q3_earnings = wayne_finance_y1["Q3_EARNINGS"], q4_earnings = wayne_finance_y1["Q4_EARNINGS"] ) wayne_finance_y2 = Finance( year = wayne_finance_y2["YEAR"], q1_earnings = wayne_finance_y2["Q1_EARNINGS"], q2_earnings = wayne_finance_y2["Q2_EARNINGS"], q3_earnings = wayne_finance_y2["Q3_EARNINGS"], q4_earnings = wayne_finance_y2["Q4_EARNINGS"] )
These Finance objects can be attached to the Company object – in a similar way to appending items to a list.
my_wayne_company.finances.append(wayne_finance_y1) my_wayne_company.finances.append(wayne_finance_y2)
Bonus points: Attach a list of Finance objects directly to the Company object.
In the previous section we had a Company object and then attached some Finance objects to it.
What if we already had several Finance objects – before we realised we needed to create a Company table? (I came across this problem recently – and it took me a bit of time to figure a clean way to do it).
Let’s look at adding a list of Finance objects directly to a Company object.
First we can create a series of Finance objects, in the same way as before:
app\api_1_0\load_junk_data.py
stark_finance_y1 = Finance( year = stark_finance_y1["YEAR"], q1_earnings = stark_finance_y1["Q1_EARNINGS"], q2_earnings = stark_finance_y1["Q2_EARNINGS"], q3_earnings = stark_finance_y1["Q3_EARNINGS"], q4_earnings = stark_finance_y1["Q4_EARNINGS"] ) : stark_finance_y4 = Finance( year = stark_finance_y4["YEAR"], q1_earnings = stark_finance_y4["Q1_EARNINGS"], q2_earnings = stark_finance_y4["Q2_EARNINGS"], q3_earnings = stark_finance_y4["Q3_EARNINGS"], q4_earnings = stark_finance_y4["Q4_EARNINGS"] )
With these 4 Finance objects created – we can create a list of Finance objects:
finance_list = [stark_finance_y1, stark_finance_y2, stark_finance_y3, stark_finance_y4]
Now that we have the finance_list created – we can create the Company object:
my_stark_company = Company( name = stark_company["COMPANY"], company_ceo = stark_company["COMPANY_CEO"], business_type = stark_company["BUSINESS_TYPE"], finances = finance_list )
We can add the list of Finance objects directly into the object instantiation.
db.session.add(my_stark_company) db.session.commit()
Finally, add them to the database.
Viewing our SQL data:
When you view your data in an SQL database browser you will see something like this – first let’s look at the “company” table:
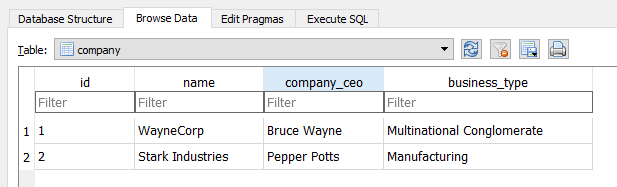
Above we can see there are 2 Company objects in our “company” table.
Next, let’s look at the “finance” table:
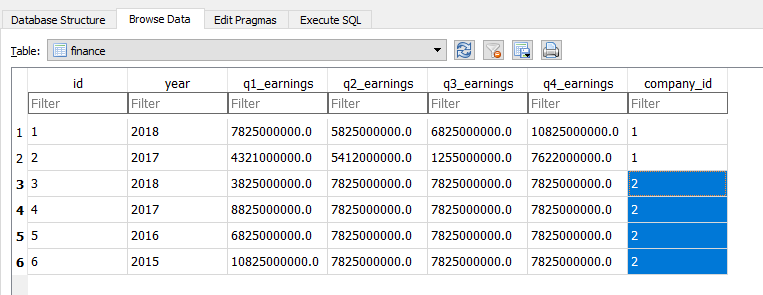
We can see there are now, 6 Finance objects stored in the “finance” table, the “company_id” column is the foreign ID , which references the respective Company ID of each Finance object.
SQL data browsers:
There are lots of programs you can use to view your SQL database:
- For development I use SQLite: SQLite browser
- In production I use PostgreSQL: pgAdmin.
(This is not an advertisement, let me know if you have any better suggestions)
(Also let me know if you want to advertise 😛 )
Blueprints.
Flask Blueprints provide a means to section off your application. They are used to organise your application into distinct components.
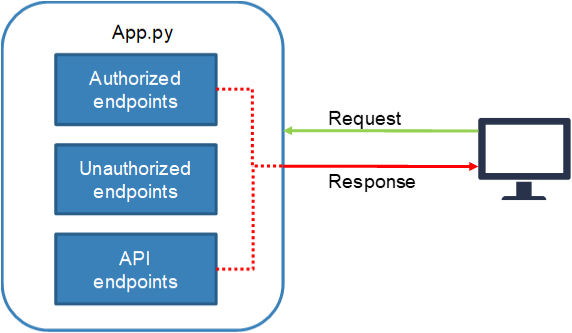
A common application pattern is to section your application into 3 distinct parts:
- Authorized endpoints:
- Returns a HTML page: Login required.
- Unauthorized endpoints:
- Returns a HTML page: Login not required.
- API endpoints:
- Returns a (usually) JSON response: Login can be required.
Adding Blueprints to your Flask project:
To use Blueprints in your app you need to first create the Blueprint and then attach it to your app.
Create Blueprint:
app/api_1_0/__init__.py
from flask import Blueprint
bp = Blueprint('api', __name__)
from app.api_1_0 import routes
What is this code doing?:
- Importing Blueprint from the flask package.
- Creating an instance of the Blueprint object.
- Importing the API endpoints from the routes.py file in the api_1_0 folder.
Attach the Blueprint to your app:
app/__init__.py
def create_app(config_class=Config): app = Flask(__name__) # Rest of your config goes here: from app.api_1_0 import bp as api_bp app.register_blueprint(api_bp, url_prefix='/api_1_0')
What is this code doing?:
- In the create_app function, (used to instantiate our application).
- We register the api_bp Blueprint with the app context.
- We’re adding a URL prefix of “/api_1_0” to this Blueprint.
Adding an API endpoint to a Flask app:
Create an API endpoint:
We’ve created the Blueprint – now lets create the api_1_0 routes file and our first API endpoint.
app/api_1_0/routes.py
First, import the Blueprint object:
from app.api_1_0 import bp
Now we can create the API endpoint:
@bp.route('/get_company/<int:id>')
@login_required
def get_company(id):
c = Company.query.filter_by(id=id).first_or_404()
message = "Welcome to the API :)"
content = {
"name" : c.name,
"ceo_name" : c.company_ceo,
"business type" : c.business_type
}
status_dict = {
"status": 200,
"success": True,
"message": message,
"contentType":'application/json',
"content": content
}
return jsonify(status_dict), status_dict["status"]
What is this code doing?:
- @bp.route(‘/get_company/<int:id>’)
- This is the Blueprint decorator.
- binds the route to our API blueprint.
- The route takes a parameter, an integer called “id”
- Login is required to access this route.
- c = Company.query.filter_by(id=id).first_or_404()
- We query the database, for the first item matching the id value.
- If no items match – we return a 404 response.
- The response from the SQLAlchemy query is stored in “c”
- content = {}
- We populate a dictionary object with the result of the query.
- status_dict = {}
- We populate a return response.
- HTTP status code 200.
- Success = True.
- A meaningful success message in the response.
- A contentType, to notify other applications we are returning a JSON resonse.
- We populate the “content” key with the dictionary object from the database response.
- return jsonify(status_dict), status_dict[“status”]
- We convert the Python dict “status_dict” into a JSON object.
- We return the status_dict JSON object and the the HTTP code.
Note: We’ve defined the route as “/get_company/id” but we’ve also added the prefix “/api_1_0” to the Blueprint – so the actual endpoint will be: /api_1_0/get_company/1 (for company ID 1).
Viewing the API respone:
With the server running, we can view the API JSON response in a web browser.
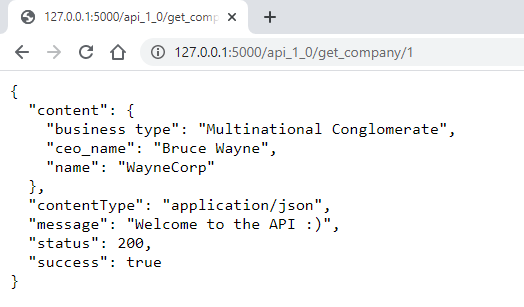
Note:
- The API Blueprints URL’s are prepended with “/api_1_0”.
- The Company ID “1” relates to WayneCorp.
Conclusion:
We looked at some Python data structures and turned these into a SQL relational data structure.
We have successfully created a Flask API, which will pull data from our database and return it as a JSON response.
We can now use this API to serve external applications or a Javascript frontend to our applications.
Resources:
Part 2 >
We’ll build on our Flask project by adding a React frontend.